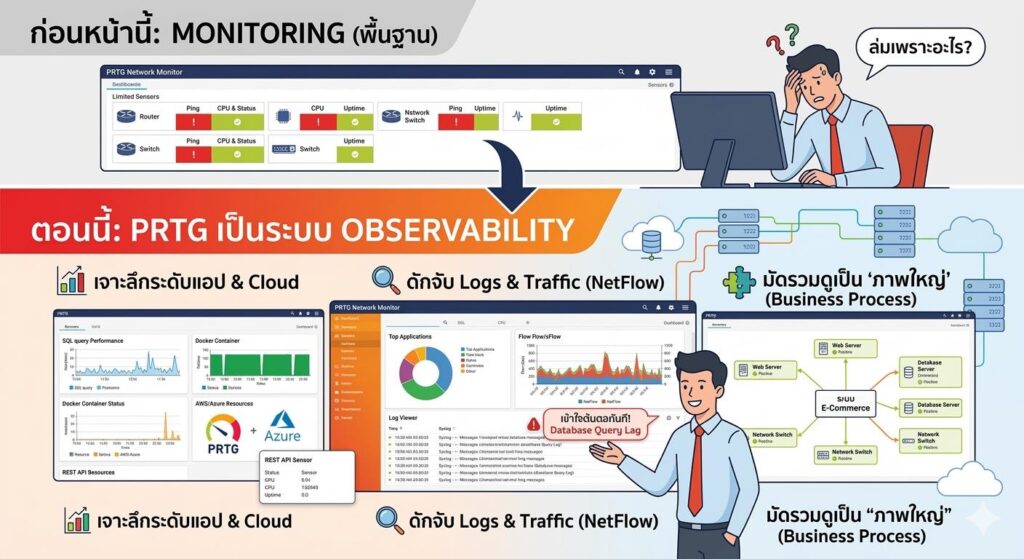
3. มัดรวมดูเป็น “ภาพใหญ่”: ทำการสร้าง Business Process Sensor ผูก Web + Database + Network เข้าด้วยกัน ล่มจุดไหน ทำให้สามรอรู้ทันทีว่ากระทบ Service อะไรของบริษัท!
Network365 Co,Ltd. website uses cookies to give you the very best experience. Cookies also help us understand how our website is being used. If you continue without changing these settings on your browser, you consent to our Cookie Privacy Policy.